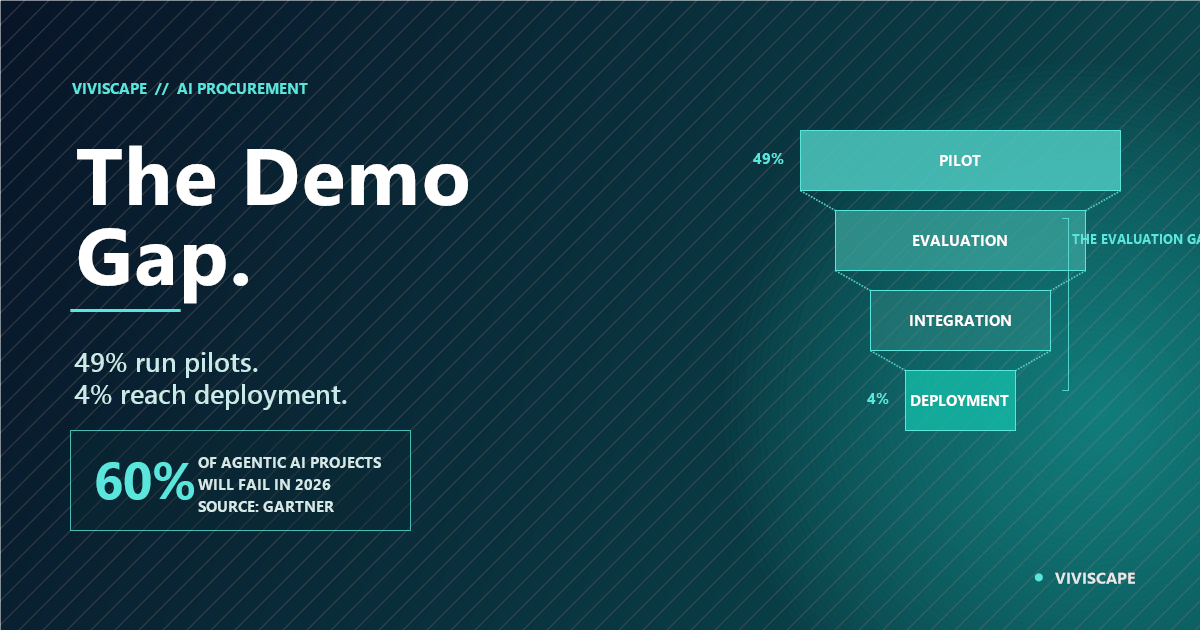
Forty-nine percent of enterprise teams are running AI pilots. Only 4% of those teams ever reach meaningful deployment. If the technology were the problem, the numbers would be different — better models produce worse deployment rates than worse models produced five years ago. The problem is not the AI. The problem is how organizations are deciding to buy it.
Enterprise AI procurement has not caught up with enterprise AI complexity. Most organizations are applying the same evaluation logic they used for SaaS tools a decade ago — impressive demos, vendor reference checks, short proof-of-concept windows — to technology decisions that require a fundamentally different kind of scrutiny. The result is a predictable pattern of $500,000 decisions made on 30-minute demos that look dramatically different in production than they did in the boardroom.
The 18-to-24-month regret window is well documented. Organizations that feel confident in their AI platform selections at contract signing are frequently reconsidering those selections before the first contract renewal. Gartner forecasts that 60% of agentic AI projects will fail in 2026 — and that the primary driver will not be model quality but data readiness and integration complexity, neither of which most procurement evaluations measure.
The Demo Problem
AI vendor demonstrations are optimized for one thing: impressiveness in controlled conditions. This is not a criticism — it is the rational response to a procurement process that rewards impressive demonstrations. The demo shows the model at its best, on curated inputs, with a skilled operator guiding the interaction, against a task that was selected because the model handles it well. The demo does not show what happens with messy real-world data, edge cases, integration failures, or the thousands of query patterns that actual users will generate over the first year of deployment.
The fundamental error is treating demo performance as a proxy for production performance. These are not correlated in any meaningful way. A model that produces extraordinary results on the twelve examples in the vendor’s script may produce mediocre results on the seventy-three query types your team actually generates. The impressive demo is evidence of what the vendor wanted you to see. It is not evidence of what you will experience at scale.
The problem compounds because most enterprise evaluation teams are not structured to test for production conditions. The team that evaluated the demo is not the same team that will be using the tool. The data used in the evaluation is not the same data the tool will need to process. The infrastructure conditions under which the demo ran are not the same conditions the tool will operate under at production load. By the time the gap becomes visible, the contract is signed and the vendor relationship is the path of least resistance.
The Four Procurement Traps
Four specific evaluation patterns account for most platform decisions that produce regret 18 to 24 months later. Each one is the result of applying legacy procurement logic to a technology category that operates differently.
Trap one: optimizing for the license cost rather than the total cost. The license fee is typically the smallest component of total AI deployment cost. Integration engineering, data preparation, security review, training, change management, and ongoing maintenance routinely exceed the license cost by a factor of three to five over a 36-month horizon. Organizations that selected the lowest-cost license frequently discover that the total cost of the deployment exceeded alternatives they considered and rejected. The initial license number is what gets presented to procurement. The rest of the costs arrive later and are harder to attribute to the original decision.
Trap two: reference checking with non-comparable organizations. Vendor reference customers are selected because they had successful deployments. They are rarely comparable to the organization doing the evaluation — different industry, different data maturity, different integration complexity, different scale. When those references report strong outcomes, it is accurate information about a deployment environment that shares almost none of the attributes that will determine success or failure in your environment. The relevant question is not “did it work for them?” but “what conditions made it work for them, and do those conditions exist in our environment?”
Trap three: POC conditions that do not replicate production conditions. The standard enterprise proof of concept runs on a clean dataset, with a limited scope, over a short timeframe, with vendor support available at every step. These conditions are structurally designed to succeed. They test whether the technology can do what it claims to do when conditions are optimized for it. They do not test whether it can handle your data quality, your integration complexity, your edge cases, or your scale. Most POC successes are accurate — the technology did perform well in POC conditions. The failure mode is in assuming that POC performance predicts production performance.
Trap four: evaluating on accuracy rather than reliability. Enterprise procurement teams evaluate AI tools on accuracy — did it get the right answer? — rather than reliability, which asks: what happens when it gets it wrong? Reliability under failure conditions is more operationally important than peak accuracy. A tool that achieves 95% accuracy but fails gracefully, produces clear error signals, and routes exceptions correctly is more deployable than a tool that achieves 98% accuracy but fails silently, produces confident wrong answers, and provides no mechanism for exception handling. Most evaluation frameworks do not test failure modes at all.
What Outcome-Driven Buying Looks Like
The organizations that are consistently reaching deployment — the 4% — are not running better technology evaluations. They are running different kinds of evaluations that measure different things.
They begin with the deployment conditions, not the technology selection. Before any vendor demo, they have documented the data environment the AI system will need to operate in: what systems it needs to connect to, what data quality they actually have (not what they wish they had), what integration architecture is required, and what the realistic timeline and cost for that integration looks like. They use that documentation to evaluate vendors against their actual conditions rather than against vendor-selected demonstration conditions.
They evaluate on production proxies rather than demo metrics. Instead of asking vendors to demonstrate on curated inputs, they provide representative samples from their actual data — messy, inconsistent, incomplete samples that reflect real conditions. They test failure modes explicitly. They require vendors to demonstrate what the system does when inputs are ambiguous, when data is missing, or when the query falls outside the training distribution. These are not hostile evaluation conditions. They are the conditions the system will face on its second week of production use.
They evaluate integration complexity as a first-class criterion, not an afterthought. The question “what does it take to connect this system to our environment?” receives the same scrutiny as “what does it do once connected?” Because the integration is where most deployments stall, organizations that do not evaluate integration complexity explicitly are systematically selecting for technologies that will perform well in demo conditions and struggle in production.
The Regret Timeline and Why It Is Predictable
Enterprise AI procurement regret follows a consistent timeline because the failure mode is consistent. The first six months after contract signing are spent on integration work that was underscoped during procurement. Month seven through twelve reveals the performance gap between POC conditions and production conditions. Month twelve through eighteen is when organizations realize the total cost of deployment has exceeded what was projected, and that the business outcomes being delivered do not match the business case that justified the purchase. Month eighteen through twenty-four is when renewal decisions become uncomfortable.
This timeline is not accidental. It reflects the natural lag between procurement decisions and the conditions under which those decisions prove themselves out. The gap is predictable enough that it should inform how procurement processes are designed — specifically, evaluation criteria should be built around what the technology will encounter at month twelve, not what it demonstrates on day one.
At ViviScape, when we help organizations evaluate AI platforms, we treat the production environment as the evaluation environment. That means conducting the evaluation against actual data, actual integration requirements, and actual failure conditions before any commitment. The upfront investment in a rigorous evaluation is a fraction of the cost of a 24-month deployment that does not deliver. The 49% who run pilots without reaching deployment have not made bad technology choices — most of the AI platforms they selected are genuinely capable. They made procurement process choices that selected for demo quality rather than deployment success.
Evaluating an AI Platform Investment?
ViviScape helps organizations structure AI evaluations that test for production conditions before procurement decisions are made — reducing integration surprises, mismatched expectations, and the regret cycle that follows most enterprise AI purchases. If you are in a platform evaluation, let’s talk before you sign.
Schedule a Free Consultation